>>> # An empty dictionary is an 8-element list! >>> d = {} 
|
>>> # This “list” of “items” is managed >>> # as a “hash table” containing “slots”
|
>>> d['ftp'] = 21 >>> b = bits(hash('ftp')) >>> print b 11010010011111111001001010100001 >>> print b[-3:] # last 3 bits = 8 combinations 001 
|
>>> d['ftp'] = 21 >>> b = bits(hash('ftp')) >>> print b 11010010011111111001001010100001 >>> print b[-3:] # last 3 bits = 8 combinations 001 
|
>>> d['ssh'] = 22 >>> print bits(hash('ssh'))[-3:] 101 
|
>>> d['ssh'] = 22 >>> print bits(hash('ssh'))[-3:] 101 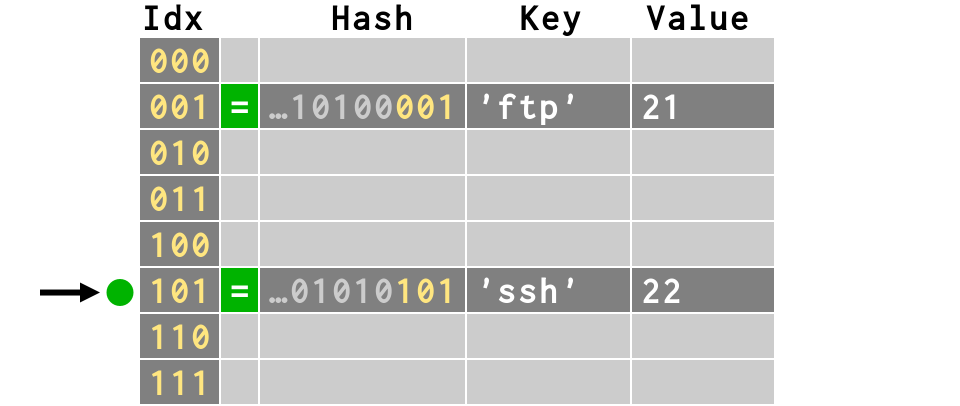
|
>>> d['smtp'] = 25 >>> print bits(hash('smtp'))[-3:] 100 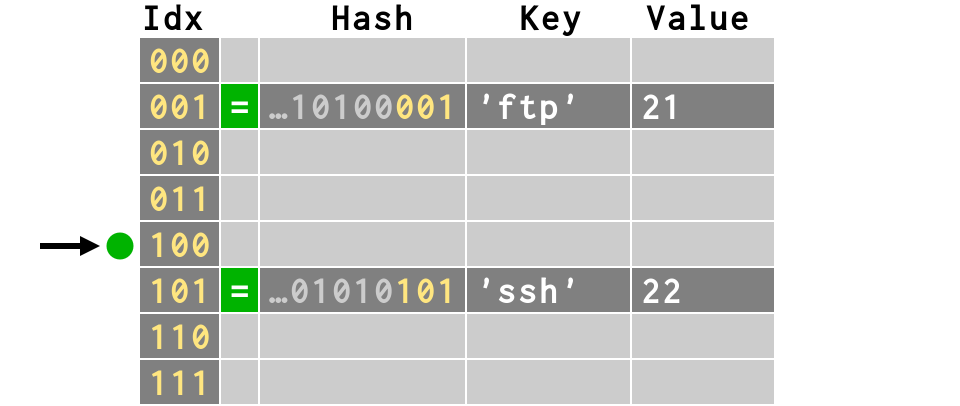
|
>>> d['smtp'] = 25 >>> print bits(hash('smtp'))[-3:] 100 
|
>>> d['time'] = 37 >>> print bits(hash('time'))[-3:] 111 
|
>>> d['time'] = 37 >>> print bits(hash('time'))[-3:] 111 
|
>>> d['www'] = 80 >>> print bits(hash('www'))[-3:] 010 
|
>>> d['www'] = 80 >>> print bits(hash('www'))[-3:] 010 
|
d = {'ftp': 21, 'ssh': 22, 'smtp': 25, 'time': 37, 'www': 80} 
|
>>> print d['smtp'] 25 >>> print bits(hash('smtp'))[-3:] 100 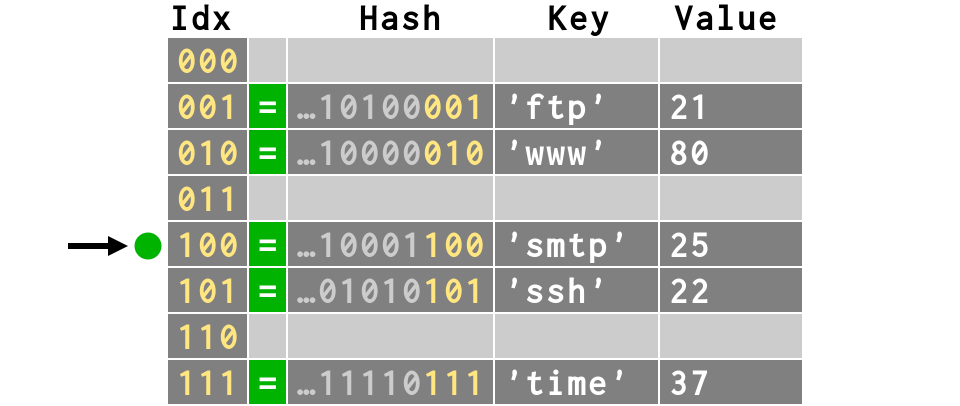
|
>>> # Different than our insertion order: >>> print d {'ftp': 21, 'www': 80, 'smtp': 25, 'ssh': 22, 'time': 37} >>> # But same order as in the hash table!
|
>>> # keys and values also in table order >>> d.keys() ['ftp', 'www', 'smtp', 'ssh', 'time'] >>> d.values() [21, 80, 25, 22, 37]
|
>>> # start over with a new dictionary >>> d = {}
|
>>> # first item inserts fine >>> d['smtp'] = 21 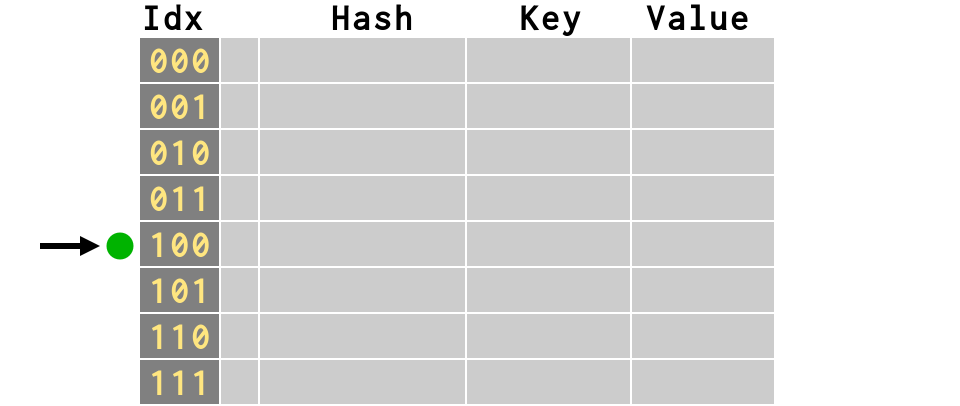
|
>>> # first item inserts fine >>> d['smtp'] = 21 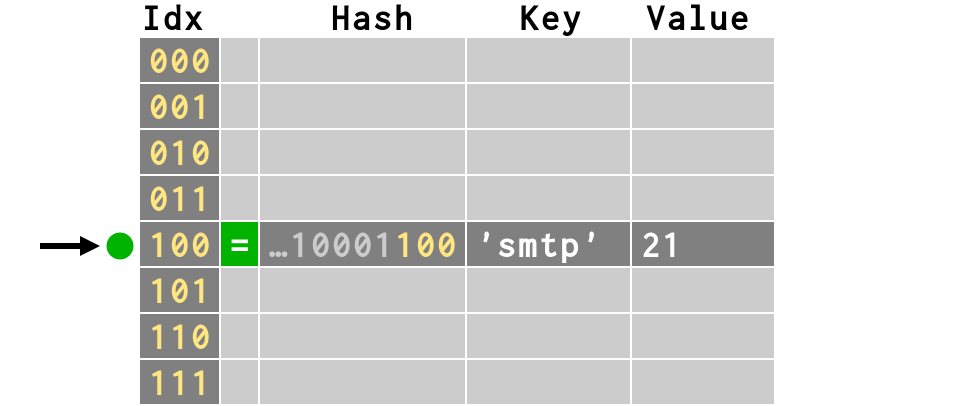
|
>>> # second item collides! >>> d['dict'] = 2628 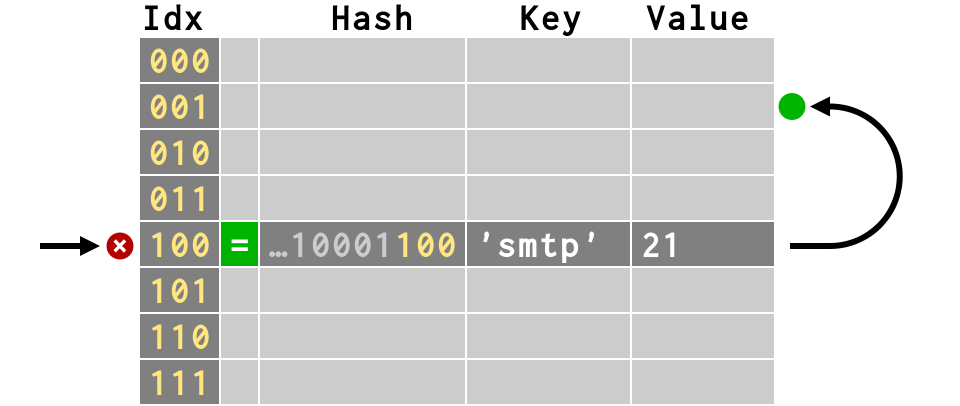
|
>>> # second item collides! >>> d['dict'] = 2628 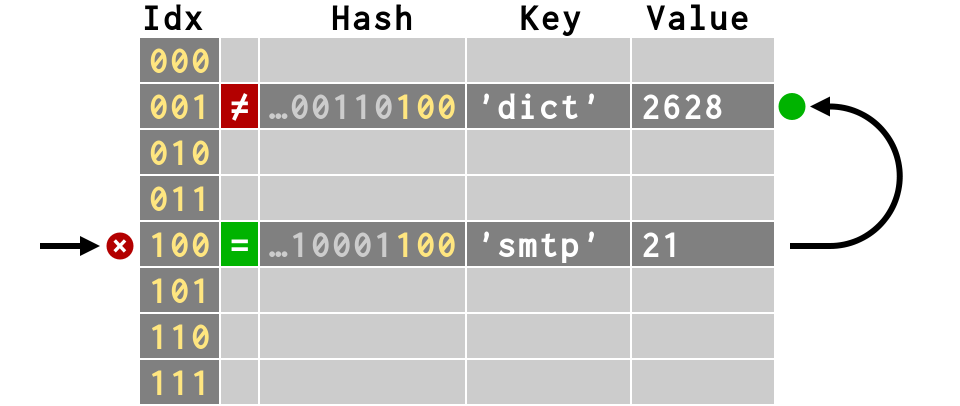
|
>>> # third item also finds empty slot >>> d['svn'] = 3690 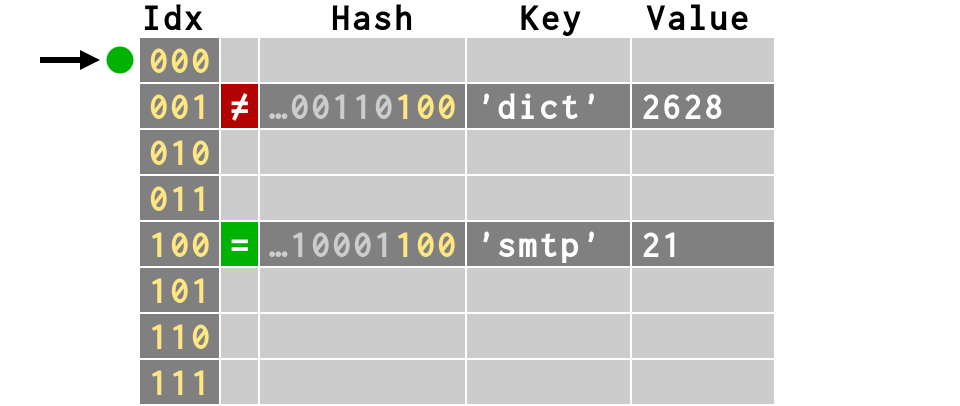
|
>>> # third item also finds empty slot >>> d['svn'] = 3690 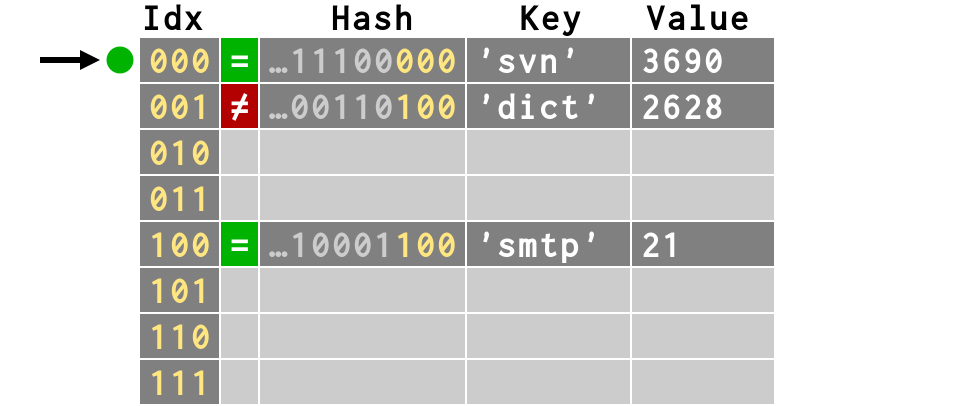
|
>>> # fourth item has multiple collisions >>> d['ircd'] = 6667 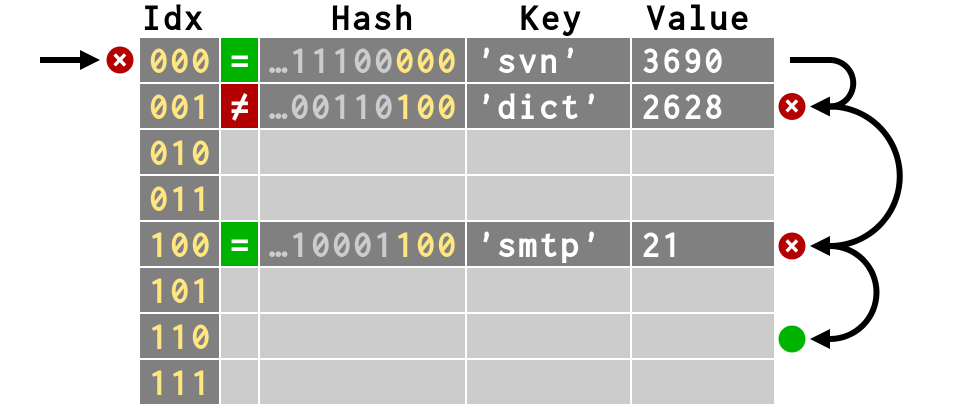
|
>>> # fourth item has multiple collisions >>> d['ircd'] = 6667 
|
>>> # fifth item collides, but less deeply >>> d['zope'] = 9673 
|
>>> # fifth item collides, but less deeply >>> d['zope'] = 9673 
|
# Only ⅖ of the keys in this dictionary # can be found in the right slot
|
>>> d = {'smtp': 21, 'dict': 2628, ... 'svn': 3690, 'ircd': 6667, 'zope': 9673} >>> d.keys() ['svn', 'dict', 'zope', 'smtp', 'ircd'] 
|
>>> e = {'ircd': 6667, 'zope': 9673, ... 'smtp': 21, 'dict': 2628, 'svn': 3690} >>> e.keys() ['ircd', 'zope', 'smtp', 'svn', 'dict'] 
|
>>> # Successful lookup, length 1 >>> # Compares HASHES then compares VALUES >>> d['svn'] 3690 
|
>>> # Successful lookup, length 4 >>> d['ircd'] 6667 
|
>>> # Unsuccessful lookup, length 1 >>> d['nsca'] Traceback (most recent call last): ... KeyError: 'nsca' 
|
>>> # Unsuccessful lookup, length 4 >>> d['netstat'] Traceback (most recent call last): ... KeyError: 'netstat' 
|
Stupid Dictionary Trick #1# Because integers hash as themselves, # we can create unlimited collisions! threes = {3: 1, 3+8: 2, 3+16: 3, 3+24: 4, 3+32: 5} 
|
Stupid Dictionary Trick #1# Thanks to piling collisions atop each # other, we can make lookup more expensive timeit('d[3]', 'd=%r' % threes) # -> 0.078 timeit('d[3+32]', 'd=%r' % threes) # -> 0.082
|
del d['smtp'] # Can we simply make its slot empty? 
|
del d['smtp'] # But what would happen to d['ircd']?
|
>>> # Creates a <dummy> slot that >>> # can be re-used as storage >>> del d['smtp'] 
|
>>> # That way, we can still find d['ircd'] >>> d['ircd'] 6667 
|
Stupid Dictionary Trick #2>>> del d['svn'], d['dict'], d['zope'] >>> d['ircd'] 6667 >>> # Still requires 4 steps! 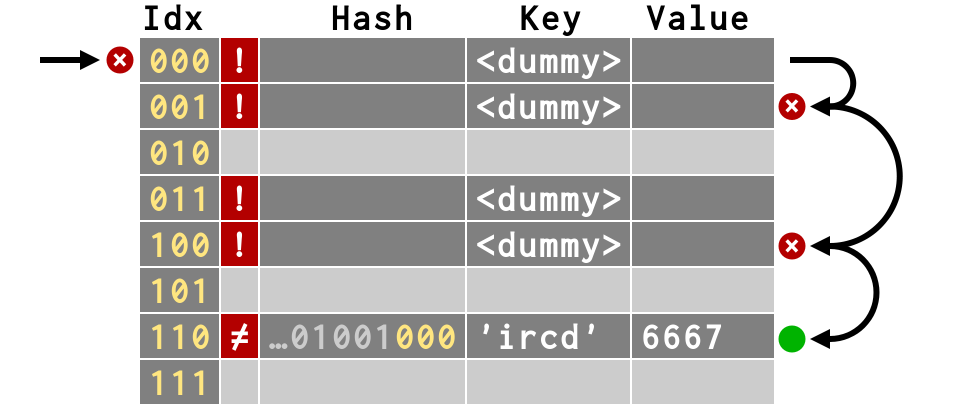
|
d = {} # Again, an empty dict has 8 slots # Let's start filling it with keys
|
d = dict.fromkeys(words[:5]) # collision rate 40% # but now ⅔ full — on verge of resizing! 
|
d['abash'] = None # Resizes ×4 to 32, collision rate drops to 0% 
|
d = dict.fromkeys(words[:21]) # ⅔ full again — collision rate 29% 
|
d['abode'] = None # Resizes ×4 to 128, collision rate drops to 9% 
|
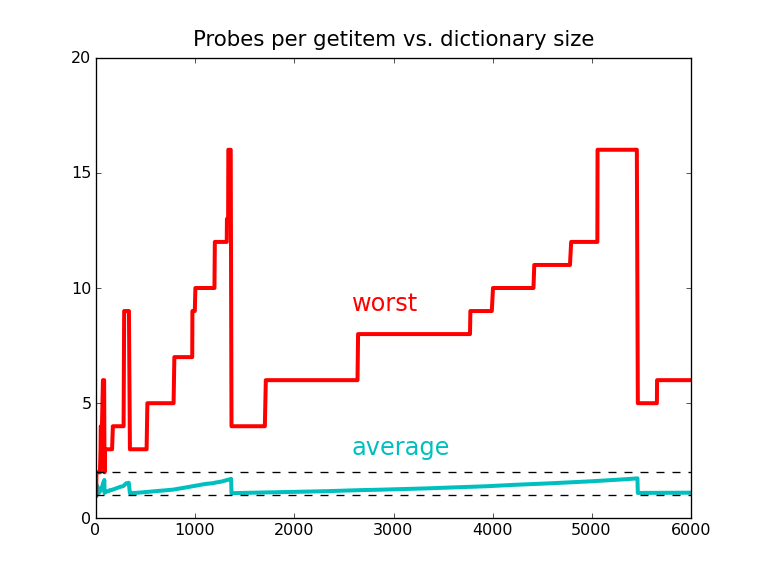
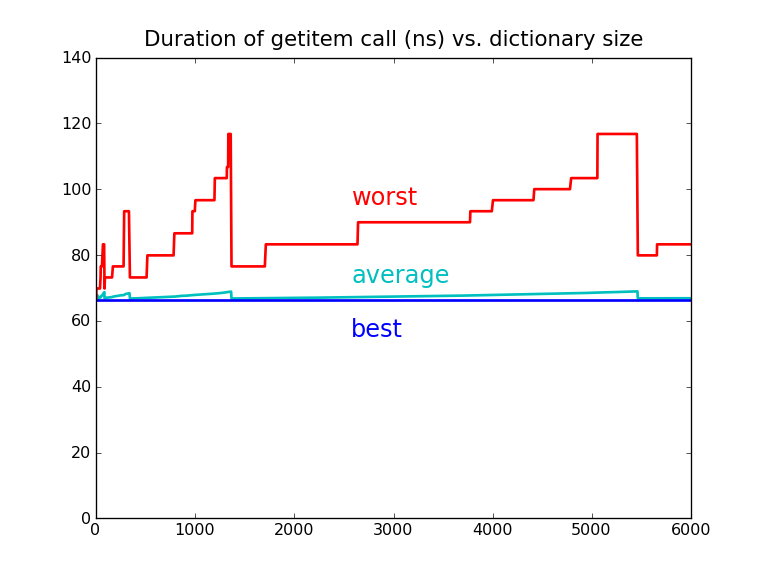
d = dict.fromkeys(words[:85]) # ⅔ full again — collision rate 33% 
|
 |
 |
The EndMay your hashes be unique,
Your hash tables never full,
And may your keys rarely collide
|