writing is migrating to plain-text with light-markup -- such as markdown, restructured-text, and asciidoc -- most especially among developers and tech people, but also authors, and soon everyone, i guarantee it.
in addition to its biggest benefit, the great flexibility, and the appeal of static blogs, a plain-text workflow also makes a promise for convenient version-control.
which makes most techies think of github, am i right?
now, anything more than convenient diffs is overkill for most writers, but since when have techies been able to resist overkill when it involves something complicated? some of them prefer to use a screwdriver to pound nails.
ergo, there are constant calls to use github for prose.
but this drumbeat ignores one very fundamental fact.
actually, it ignores a dozen; but let’s focus now on one:
github diff routines just don’t work well for prose.
and even when the algorithms work acceptably well, the display of your diffs is often “less than ideal”...
indeed, it was only in december of 2013 that paragraphs on github prose diffs started to be wrapped; before then, i guess you needed to do horizontal scrolling to see them. (and i think everyone agrees the horizontal-scroll is evil.)
https://github.com/blog/1707-soft-wrapping-on-prose-diffs
it was another 9 months later before side-by-side diffs and, more importantly, word-highlighted diffs, were introduced.
https://github.com/blog/1884-introducing-split-diffs
https://github.com/blog/1885-better-word-highlighting-in-diffs
these huge advances came right after github put on sale its t-shirts, which might tell us about the priority of prose.
https://github.com/blog/1883-new-in-the-shop-github-flow-shirts
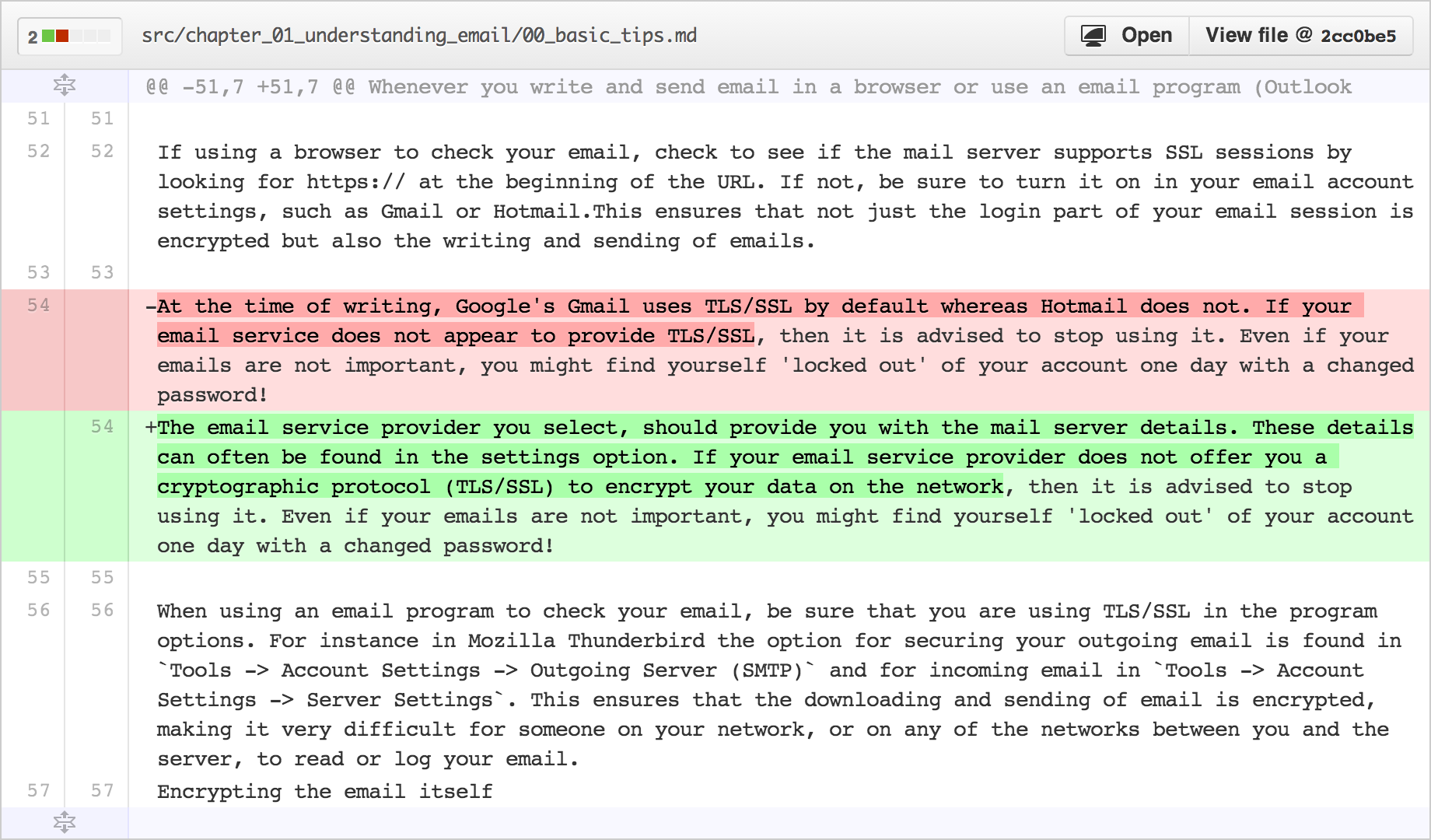
but even now, with those improvements, there are flaws with the display of prose diffs in github. if you add a few words inside a paragraph, it can often cause the words which follow to misalign, relatively, in the “before” and “after” displays. (you see a small example of this even in the graphic above.)
and if you add a lot of stuff, it might all go way out of whack.
it is fairly well-recognized that things would operate better if each sentence in the text was placed on a separate line.
not only might the change-algorithms work more smoothly, but the display-of-diffs would also be significantly improved.
it’s simple: one sentence per line.
some people -- dating to the illustrious brian kernighan -- argue that this makes it easier to rewrite and edit as well, as “most people change documents by rewriting phrases and adding, deleting and rearranging sentences.” astute. (but he could benefit from some judicious oxford commas.)
in accordance with his observation, kernighan also advised that we “make lines short, and break lines at natural places, such as after commas and semicolons, rather than randomly.”
for pointers to this, google’s top return gives “semantic lines”:
http://rhodesmill.org/brandon/2012/one-sentence-per-line/
brandon rhodes notes that we should remember that we can “add linefeeds anywhere that there is a break between ideas.”
the best summary is: use linebreaks to split on phrases.
as someone who has used this practice for many decades now, i can assure you it’s a useful one during the course of re-writing.
but whether or not you choose to write in this particular way -- maybe you have reasons not to, or can’t get in the habit, or you probably just think it looks weird and it freaks you out -- there is no dispute that it makes version-tracking diffs better.
so you might not want to write that way, but you might like to have your text be in that format for better version-tracking.
good news: you can have it both ways! just call "breakerbreaker".
use this little javascript routine to break text into phrases...
//
// breakerbreaker -- a routine to break text into phrases
//
var s=$("#theinput").val()
//
// #1 -- regularize line-endings and delete trailing spaces
//
while (s.indexOf("\r\n")
-1) {s=s.replace(/\r\n/g,"\n")}
while (s.indexOf("\r")
-1) {s=s.replace(/\r/g,"\n")}
//
while (s.indexOf(" \n")
-1) {s=s.replace(/ \n/g,"\n")}
//
// #2 -- introduce space/linebreak combination at phrases
//
s=s.replace(/\. /g,". \n")
s=s.replace(/, /g,", \n")
s=s.replace(/; /g,"; \n")
s=s.replace(/: /g,": \n")
s=s.replace(/\? /g,"? \n")
s=s.replace(/! /g,"! \n")
s=s.replace(/\" /g,'" \n')
s=s.replace(/\) /g,") \n")
//
s=s.replace(/ \"/g,' \n"')
s=s.replace(/ \(/g," \n(")
//
s=s.replace(/ -- /g," \n-- \n")
//
s=s.replace(/ about /g," \nabout ")
s=s.replace(/ also /g," \nalso ")
s=s.replace(/ and /g," \nand ")
s=s.replace(/ as /g," \nas ")
s=s.replace(/ because /g," \nbecause ")
s=s.replace(/ between /g," \nbetween ")
s=s.replace(/ both /g," \nboth ")
s=s.replace(/ but /g," \nbut ")
s=s.replace(/ by /g," \nby ")
s=s.replace(/ could /g," \ncould ")
s=s.replace(/ ever /g," \never ")
s=s.replace(/ for /g," \nfor ")
s=s.replace(/ from /g," \nfrom ")
s=s.replace(/ have /g," \nhave ")
s=s.replace(/ how /g," \nhow ")
s=s.replace(/ if /g," \nif ")
s=s.replace(/ in /g," \nin ")
s=s.replace(/ inside /g," \ninside ")
s=s.replace(/ into /g," \ninto ")
s=s.replace(/ is /g," \nis ")
s=s.replace(/ may /g," \nmay ")
s=s.replace(/ might /g," \nmight ")
s=s.replace(/ minus /g," \nminus ")
s=s.replace(/ must /g," \nmust ")
s=s.replace(/ never /g," \nnever ")
s=s.replace(/ of /g," \nof ")
s=s.replace(/ on /g," \non ")
s=s.replace(/ only /g," \nonly ")
s=s.replace(/ or /g," \nor ")
s=s.replace(/ outside /g," \noutside ")
s=s.replace(/ plus /g," \nplus ")
s=s.replace(/ should /g," \nshould ")
s=s.replace(/ that /g," \nthat ")
s=s.replace(/ their /g," \ntheir ")
s=s.replace(/ to /g," \nto ")
s=s.replace(/ was /g," \nwas ")
s=s.replace(/ what /g," \nwhat ")
s=s.replace(/ when /g," \nwhen ")
s=s.replace(/ where /g," \nwhere ")
s=s.replace(/ whether /g," \nwhether ")
s=s.replace(/ which /g," \nwhich ")
s=s.replace(/ who /g," \nwho ")
s=s.replace(/ why /g," \nwhy ")
s=s.replace(/ will /g," \nwill ")
s=s.replace(/ with /g," \nwith ")
s=s.replace(/ without /g," \nwithout ")
s=s.replace(/ would /g," \nwould ")
//
$("#theoutput").val(s)
after regularizing all your line-endings to the standard “\n” (which might be unnecessary, but let’s make sure anyway), "breakerbreaker" then removes any errant “trailing spaces” -- i.e., each space directly preceding a linebreak -- which is something that you shouldn’t have in your text-file anyway. (um, yes, if you are using that stupid markdown convention where 2 spaces at the end of the line force a hard-linebreak, do yourself a favor and change ’em to “<br>” forevermore.)
then "breakerbreaker" places a space/linebreak combination next to various “strings” which will typically set off phrases -- punctuation, conjunctions/disjunctions, prepositions, etc.
the best way to think of this space/linebreak combination is it represents the equivalent of a word-processor soft-return.
(except, of course, github still sees a “\n” as a hard-return, so the diff-display will show a sequence of fairly short lines.)
as a little example, here’s what the first four paragraphs from this article look like after they have been through this routine:
writing
is migrating
to plain-text
with light-markup
--
such
as markdown,
restructured-text,
and asciidoc
--
most especially among developers
and tech people,
but also authors,
and soon everyone,
i guarantee it.
in addition
to its biggest benefit,
the great flexibility,
and the appeal
of static blogs,
a plain-text workflow
also makes a promise
for convenient version-control.
ergo,
there are constant calls
to use github
for prose.
but this drumbeat ignores one very fundamental fact.
if you want to use “breakerbreaker” on some of your own text, you can fire up the demo program which you find located here:
http://zenmagiclove.com/simple/breakerbreaker.htmlthat’s also a good place to grab the script -- just “view source”...
http://zenmagiclove.com/simple/breaker.htmlit’s also on medium, here:
http://zenmagiclove.com/simple/breakerbreaker.html
when a “breakerbreaker” text is diffed, results stand out clearly.
but there’s more beauty to come.
because you’re probably thinking that, even if the diffs are fine, you don’t really wanna work with a text-file that looks like this, what with all your paragraphs being chopped into short lines.
the thing is, you don’t have to.
because this conversion is easily reversed with one global change: simply change the occurrences of space/linebreak back to a space.
and, voila!, your text is back to its original state, ready for edits.
in the meantime, you receive a diff which is extremely clear.
before check-in, run “breakerbreaker”; on check-out, re-join.
of course, github could just insert this script in its diff workflow, and create better diffs for you without you doing all this “work”.
maybe you can convince them of that; no, i can’t help you there.
but you’re still able to go through the process by yourself, so i hope this simple idea helps you get better diffs in the future.
just to be “meta,” i will put “breakerbreaker” up on github. you can find it here, and “fork it,“ or whatever you kids do. try it out, and if you have any suggestions for improvement, get in the game!
https://github.com/bbirdiman
-bowerbird
p.s. i’ve done much work on this, if you are interested...
some of the work originated with project gutenberg e-texts, text-lines obtained by o.c.r. done on paper-book page-scans, analyzing diffs resulting between various rounds of proofing.
you can see an example on these webpages:
http://zenmagiclove.com/misc/weball.html
http://zenmagiclove.com/misc/webone.html
and i wrote this later, on version-control change-tracking:
http://zenmagiclove.com/phrase-change-display.html
http://zenmagiclove.com/phrase-change-sample.html
and here’s some version-tracking on the gettysburg address:
http://zenmagiclove.com/misc/gabal/gabal.html